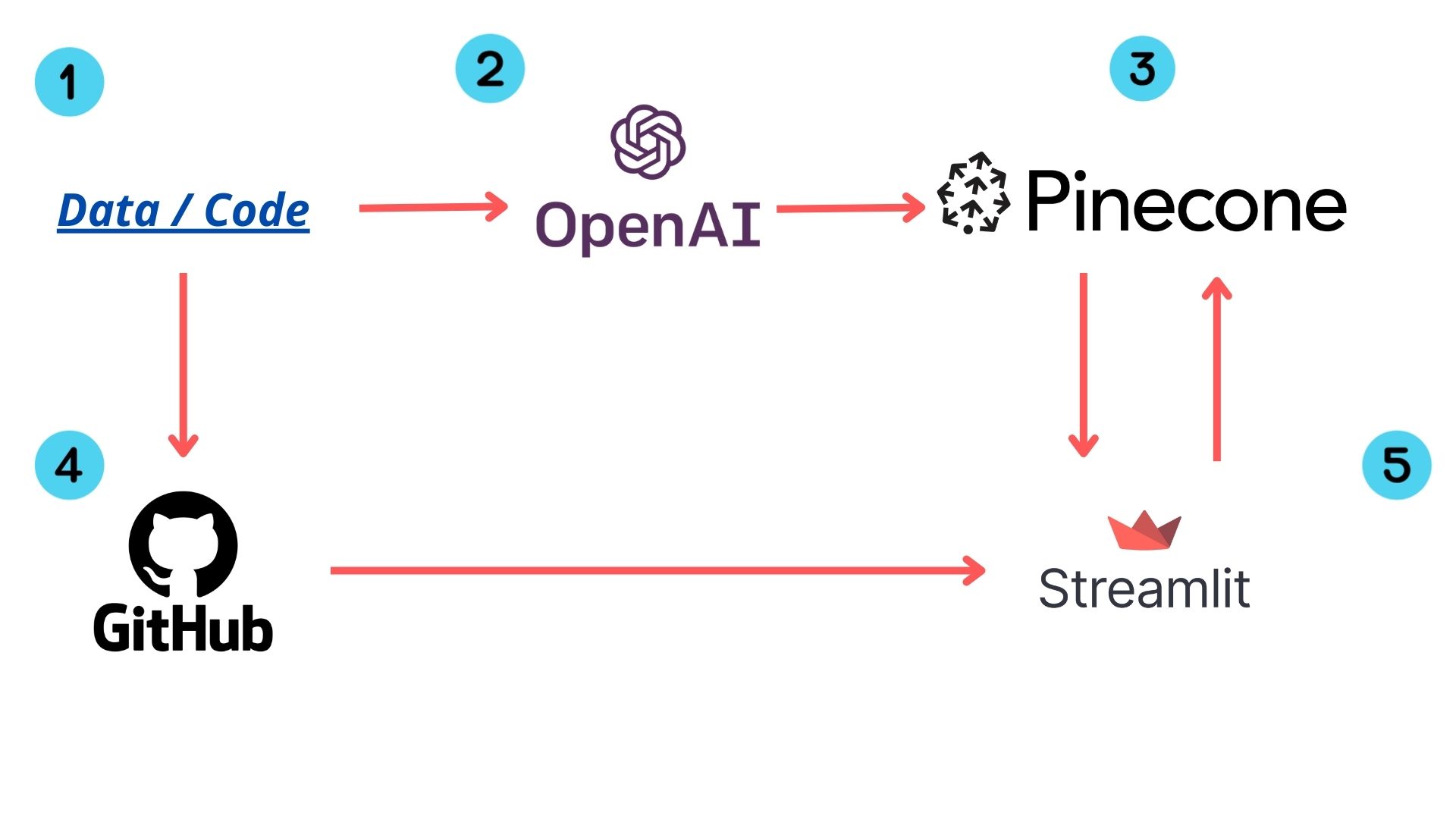
Books Recommender System
Introduction
Recommender Systems play a crucial role in cross-selling and reducing customer churn across many industries. In cases where text data is available, recommender systems can identify semantic similarities among documents to find the most similar ones.
The text is converted into embeddings, which are dense representations. These vectors can effectively represent many words in a context window. The length of the context window depends on the capabilities of the embeddings model.
The objective of this work was to create a recommender system based on semantic embeddings to suggest similar books based on their descriptions and categories.