Improving Marketing for Politic Campaigns
Introduction
Data-driven decision making is a way to improve organizations and save money. Many politics in developing countries do not consider the importance of data available in social media. Social media provides information of how people are thinking about a candidate. This data helps to improve the public image of the candidate and gain more votes.
This work used an API from the website Apify. The API used let to extract information from Facebook. The data extracted were the post descriptions, likes, comments, and shares. Three candidates for a mayoral position were evaluated from April to November of 2022. The identities are going to be hidden in all the analysis to protect client’s privacy.
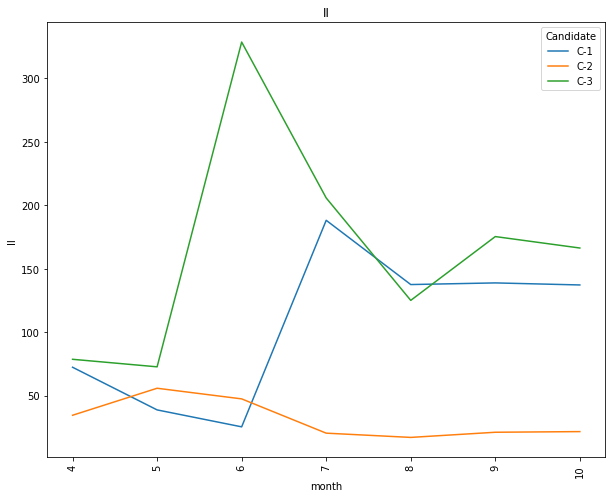
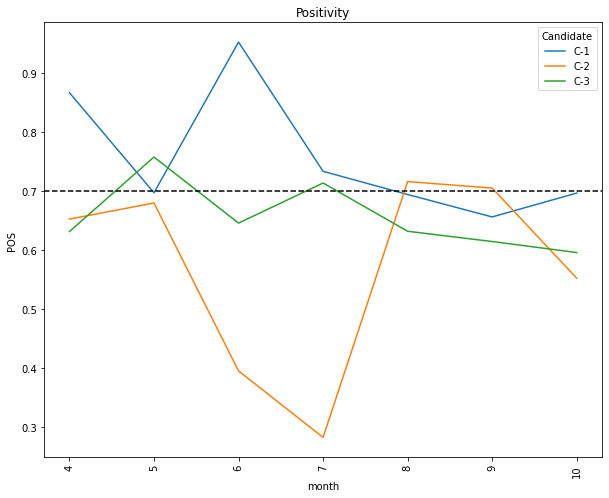
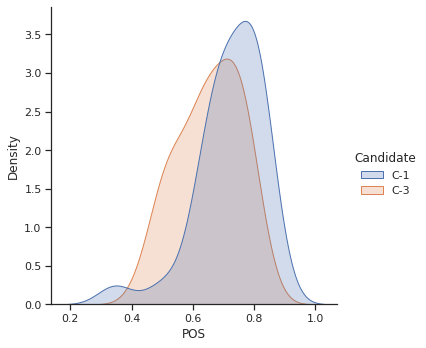
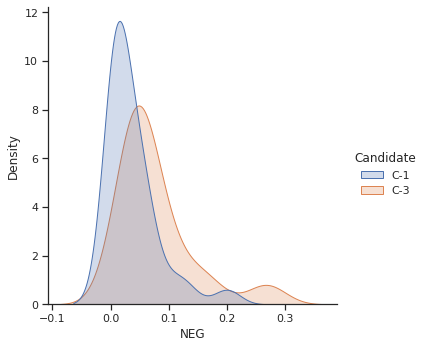
The goal was identify outliers of high popularity, positivity and negativity. The results proofs what already worked out in the campaing and what did not.