Main Topic Identification
Introduction
Unstructured text data play a crucial role in people's daily lives. However, the sheer volume of data generated makes it unfeasible to label manually. Therefore, it is necessary to develop a machine learning model to perform this task.
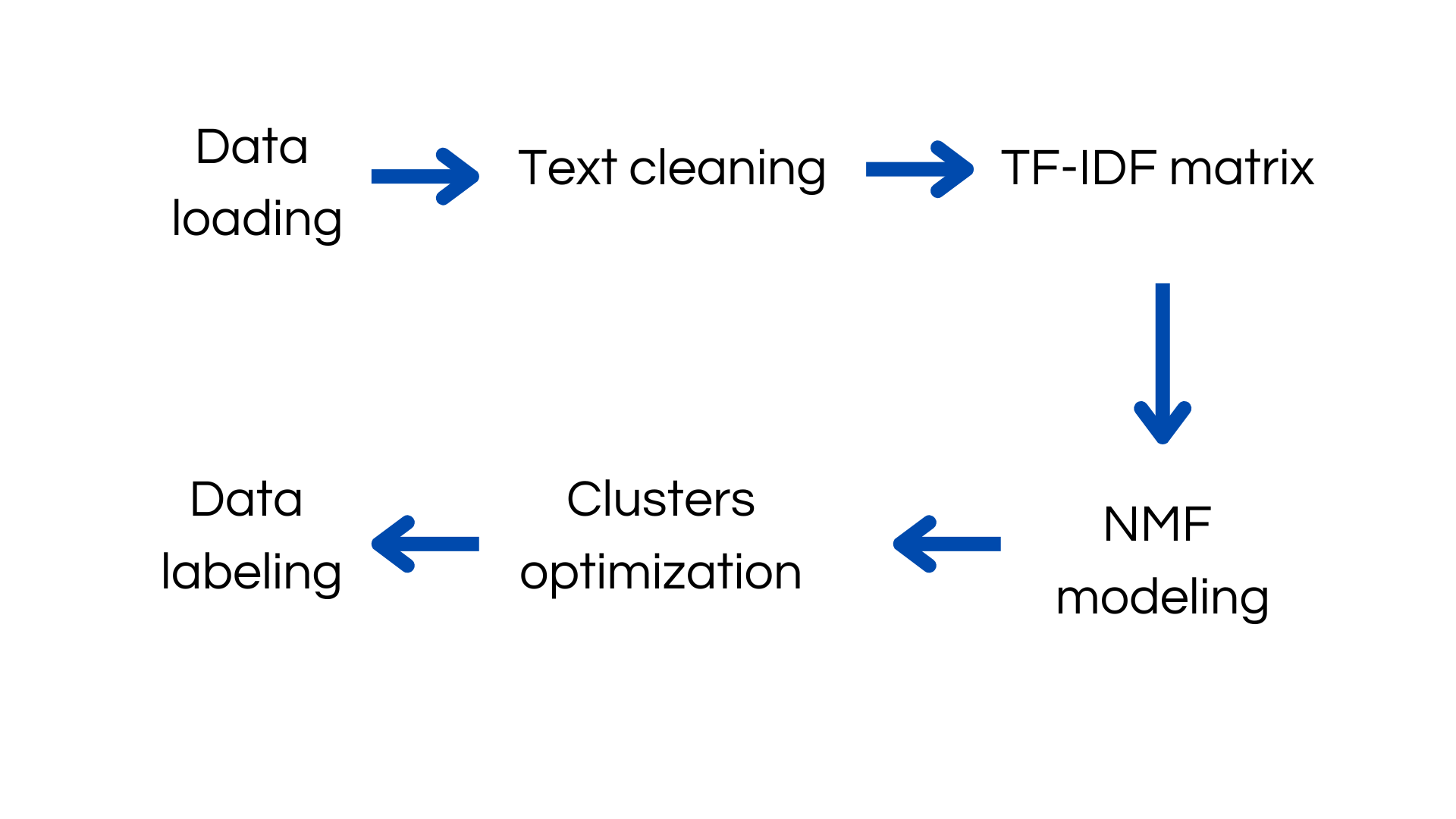
Main Topic Identification helps us cluster data with similar words to assign labels and categorize the data. This can be achieved using various techniques, with one of the most popular being Non-Negative Matrix Factorization (NMF).
NMF creates "k" features from a sparse representation, using a TF-IDF matrix for text. Afterward, we identify the top-10 words for each "k" feature developed. With human inspection of the obtained clusters, we assign labels to the clusters and then apply these labels to all documents.